VEX IR学习
2023-02-Update:很早之前想要重新整理一下来着,一直鸽着。希望今年五月份可以完成orz
搞这个的原因是课题那边,把基本块转成VEX IR后需要进行一些modify。老师:你这周就先把VEX IR (和LLVM IR )看懂
所以这篇的要求也就是能看懂和在变量名之类的做一点优化(统一)就行了
代码1
从程序里转了一段中间代码:
1 | IRSB { |
angr输出的反编译代码:
1 | >>> irsb.pp() |
对应ida中选中的部分:
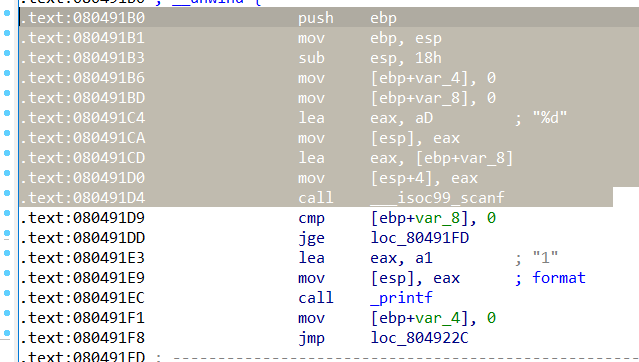
分析1
首先第一行表示函数的开始(IRSB在此处无意义)
IRSB:
后续的一堆tx:Ity blabla 代表临时变量,同时指明了变量类型
1 | quote:Temporary variables. VEX uses temporary variables as internal registers. |
IMark没有实际意义,仅作为一个statement,括号中的内容分别代表了在程序中的起始地址、指令长度和(不知道,不过只见过值=0)
对寄存器操作前需要读取该寄存器[GET]
操作结束后将值写回[PUT]
t0 = GET:I32(ebp):t0 gets ebp, which is a 32bit integer
t12 = Sub32(t13,0x00000004): t12 = t13 - 0x4
PUT(esp) = t12: esp = t12
[Update a register with the value of the given IR Expression.]
STle(t12) = t0: [t12] = t0
Update a location in memory, “le” in STle (and LDle) stands for “little-endian”
1 | 0~7行大概干了个 |
09行的命令很直白,但10~15指的是啥呢…似乎跟10~13出现的"cc_*"有挺大关系,但“cc_”只出现在arm架构的文档中:
1 | # NOTE 2: Something is goofy w/r/t archinfo and VEX; cc_op3 is used in ccalls, but there's |
17~22对应了:
1 | mov [ebp-4], 0 |
t15=t12+0xfffffffc,此时t12=ebp。看起来很奇怪,但其实把t15指向了ebp-4的位置,(不过为啥不用减法了?…)
24~26行实现了两条语句:
1 | 0x80491c4: lea eax, [0x804a021] |
24行:没有实际意义
26行:
此时t2=esp,把esp指向的值改为0x0804a021d
相当于mov [esp],[0x804a021]
所以其实是再进行了优化的(可能这就是RISC吧…)
28~34:
1 | 0x80491cd: lea eax, [ebp - 8] |
但并没有像上面一样绕过eax,直接对内存的进行修改,应该是因为针对一个基本块分析的时候要保存寄存器最后的值,不能再优化了
最后的跳转:
放一个官方对于跳转命令的整理
1 | typedef |
代码2
1 | IRSB { |
对应汇编代码
1 | 0x80491fd: cmp dword ptr [ebp - 8], 0xa |
suprise…汇编好简洁
03行:t2=[t4]
1 | LDle:The value stored at a memory address, with the address specified by another IR Expression. |
11行:
1 | Iop_1Uto32, /* :: Ity_Bit -> Ity_I32, unsigned widen */ |
看一下寄存器的定义,t14的大小也是一个bit
所以这个命令的作用就是把它扩展成32位的无符号数,放到t13里
13行:
1 | Iop_32to1, /* :: Ity_I32 -> Ity_Bit, just select bit[0] */ |
再取最低位放到t15里
讲真没看懂这波操作为啥要这么多次转换
分析3_来波大的
1 | >>> irsb.vex.pp() |
angr的汇编代码
1 | >>> irsb.pp() |
这段代码是
1 | int a[] = {1,2,3,4,5}; |
的循环部分
01~04:执行后
1 | t26=rbp-0x2c |
结合下一步的操作,不是很懂意义何在…
11行:出现了vex ir 指令,Sto,S指的是singed widen;类似的Uto中,U指的是unsigned widen
对于这行代码的理解可以参考汇编中的movsxd:
1 | MOVSXD r64, r/m32 Move doubleword to quadword with sign-extension. |
到57行前都是些重复的语句
57行:
mul64:官方文档中写道,mul代表的是signless的,相对的有以下乘法:
1 | /* -- Ordering not important after here. -- */ |
看到这行产生了个疑惑:imul是带符号的,但mul64是个无符号的乘法
再往下看看,发现,
1 | t16=Mul64(t78,t68) |
完成了以下三条汇编指令:
1 | 0x401189: imul rcx, rdx |
sar64:官方文档中没有描述作用,猜测和x64汇编相似,即算术右移(用符号位补)
cqo:将rax中的符号复制到rdx的每个位上
64~70行:
简单的一条
1 | idiv rcx |
被转换成了七行ir
1 | 64 | t84 = 64HLto128(t81,t16) |
涉及到了几个没有见过的VEX IR 指令:
64HLto128:两个64位的寄存器里的值组合扩展到128位的寄存器中
DivModS128to64::: V128,I64 -> V128,of which lo half is div and hi half is mod
128HIto64:128位数据中的高64位复制到64位寄存器中
82~85行,出现了“cc_*”的“寄存器”,但似乎对理解这个基本块的VEX IR完全没有影响…(不会是因为代码片段还不够长吧orz)
第二段
1 | >>> irsb.vex.pp() |
第一部分13行:cmpLT32S
官方文档中的解释很短:
1 | /* Standard integer comparisons */ |
该结果为在x86汇编中为指令jge服务(大于等于则跳转)
所以小于3时t8=t20=t16=1
因此cmpLT应该是“前小于后返回1”
所以"CmpL*"是只能比较小于或等于?
注:试了一下还真是这样的,形成的中间代码会把其他判断方式转换成"<“/”="
注2:在微软的文档搜到了SSE2指令集,里边的比较指令和 vex ir 长得还蛮像的↓
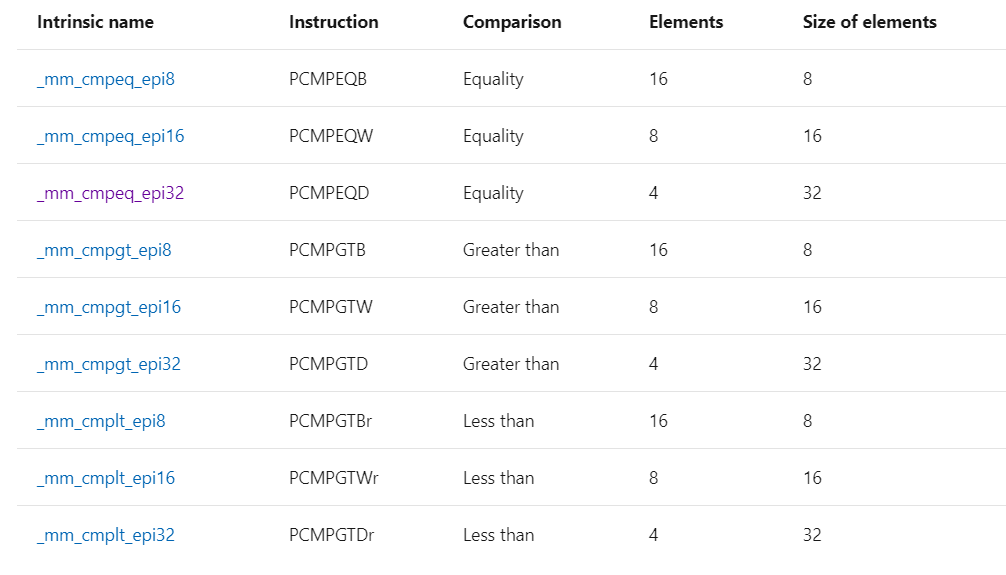
来个aarch64的
用aarch64-linux-gnu-gcc编译了相同的代码:
1 |
|
用angr加载的时候会产生警告,但(对于这个样例)没有影响
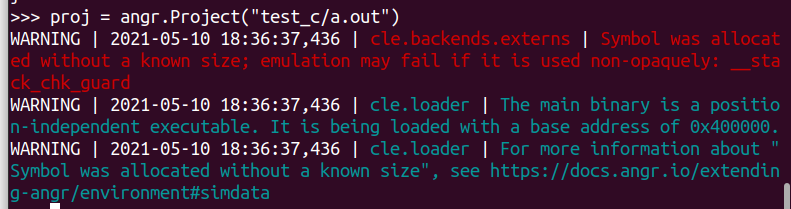
注:上一个应该是因为找不到动态链接库,编译选项设置静态编译后可以正常加载
发现vex ir用到的寄存器是根据程序cpu架构改变的。如i386、amd64下用到PUT(rip)、PUT(eip),在aarch64下则是PUT(pc)
选取下面这句代码的中间代码:
1 | *(_DWORD *)(qword_4999C8 + 4) = aa; |
aarch64
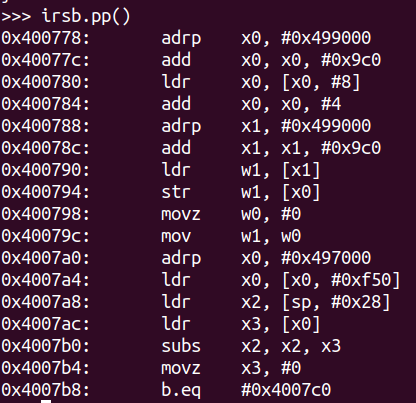
1 | 00 | ------ IMark(0x400778, 4, 0) ------ |
amd64
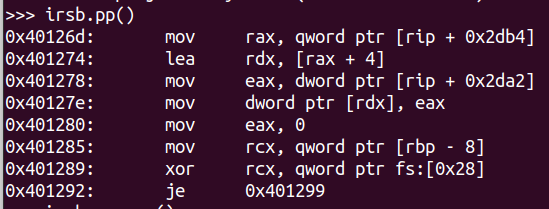
1 | 00 | ------ IMark(0x40126d, 7, 0) ------ |