堆学习
堆相关数据结构
微观结构
malloc_chunk
程序malloc出的内存称为chunk,在ptmalloc内部用下面的结构体表示,内存空间释放后被加入空闲管理列表。一个chunk不论是分配还是释放,结构都相同。
malloc_chunk结构体
1 | struct malloc_chunk { |
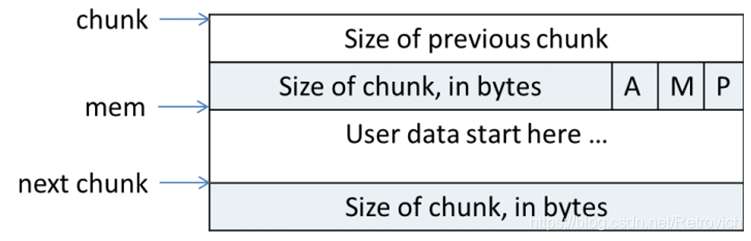
一般chunk size表示malloc_chunk的实际大小,而chunk unused size 表示该chunk中除了prev_size、size、fd等辅助成员外的实际大小
bin
bin是由chunk结构体组成的链表,按照chunk的大小来管理free后的chunk
bin链主要有以下几类,其中只有fast bin是单链表,其他都是双向链表。
对于small bins,large bins,unsorted bins来说,ptmalloc将它们维护在同一个数组中,对应的数据结构在malloc_state中
fast bin
不属于bins,是ptmalloc单独管理小堆块的数据结构,如果free的chunk大小在0x20~0x80,会优先进入fastbin
采用LIFO,用于较小的内存块。当用户需要的chunk大小小于ptmalloc的最大大小时,ptmalloc先判断fastbin中是否有对应大小的空闲块。
fastbin中的chunk的inuse始终置为1,不会与其他chunk合并。但如果相邻的chunk合并后的大小大于某个值(FASTBIN_CONSOLIDATION_THRESHOLD),就需要把fastbin中的chunk合并(内存碎片)
fastbinsY数组中每个fastbin元素指向该链表的尾节点,尾节点通过fd指针指向前一个节点
small bin
采用FIFO,有62个循环双向链表,每个下标对应的chunk大小都一致,关系为
1 | x(下标) 2*4*x(32位) 2*8*x(64位) |
其中每个链表都有链表头结点
fastbin与smallbin中的chunk的大小有很大一部分会重合,fastbin中的chunk很有可能被放到smallbin中
large bin
包括63个bin,每个bin中的chunk大小不一致。将63个bin分成6组,每组bin中的chunk大小的公差(最大-最小)一致
| 组 | 数量 | 公差 |
|---|---|---|
| 1 | 32 | 64B |
| 2 | 16 | 512B |
| 3 | 8 | 4096B |
| 4 | 4 | 32768B |
| 5 | 2 | 262144B |
| 6 | 1 | 不限制 |
其中所有chunk按照从大到小排列
unsorted bin
采用FIFO可以视作空闲chunk回归所属bin前的缓冲区unsorted bin只有一个链表。其中的chunk处于乱序状态,主要有两个来源:
- 较大的chunk被分割后,剩下的部分大于minsize
- 释放一个不属于fastbin的chunk,并且该chunk不与top chunk相邻
top chunk
程序第一次进行malloc时,heap会被分为两块,其中一块就是top chunk。top chunk即当前堆的物理地址最高的chunk,不属于任何一个bin,只用于在所有bin不满足请求大小时进行分配(如果大小满足),然后将剩下的部分作为top chunk,否则就对heap进行扩展然后再分配(原来的top_chunk紧接着进入unsorted bin,这里可能产生漏洞),在main_arena中通过sbrk扩展,在thread_arena中通过mmap扩展。
topchunk的prev_inuse位始终为1
last remainder chunk
当用户请求的是一个small chunk,且该请求无法被small bin、unsorted bin满足的时候,就通过binmaps遍历bin查找最合适的chunk,如果该chunk有剩余部分的话,就将该剩余部分变成一个新的chunk加入到unsorted bin中,另外,再将该新的chunk变成新的last remainder chunk
此类型的chunk用于提高连续malloc(small chunk)的效率,主要是提高内存分配的局部性。那么具体是怎么提高局部性的呢?举例说明。当用户请求一个small chunk,且该请求无法被small bin满足,那么就转而交由unsorted bin处理。同时,假设当前unsorted bin中只有一个chunk的话——就是last remainder chunk,那么就将该chunk分成两部分:前者分配给用户,剩下的部分放到unsorted bin中,并成为新的last remainder chunk。这样就保证了连续malloc(small chunk)中,各个small chunk在内存分布中是相邻的,即提高了内存分配的局部性。
宏观结构
在glibc malloc中针对堆管理,主要涉及到以下3种数据结构:
- heap_info: 即Heap Header,因为一个thread arena(注意:不包含main thread)可以包含多个heaps,所以为了便于管理,就给每个heap分配一个heap header。在当前heap不够用的时候,malloc会通过系统调用mmap申请新的堆空间,新的堆空间会被添加到当前thread arena中,便于管理。
- malloc_state: 即Arena Header,每个thread只含有一个Arena Header。Arena Header包含bins的信息、top chunk以及最后一个remainder chunk等
- malloc_chunk: 即Chunk Header,一个heap被分为多个chunk,至于每个chunk的大小,这是根据用户的请求决定的,也就是说用户调用malloc(size)传递的size参数“就是”chunk的大小.每个chunk都由一个结构体malloc_chunk表示
Arena
一个线程只有一个arena,各个线程的arena都是独立的。
每个程序中的arena数量是有限制的,与和核心数量有关,因此不是每个线程都会有独立的arena。另外,如果线程数大于核心数的两倍,就必然有线程处于等待状态,所以没有必要都分配独立的arena
主线程的arena称为main_arena;子线程的称为thread_arena。
与 thread arena 不同,main arena 的 arena header(state) 不是保存在通过 sbrk 申请的堆段里,而是作为一个全局变量,可以在 libc.so 的数据段中找到
heap info
专门为mmap申请的内存(memory mapping segment)准备的,用来记录堆的信息和链接结构
1 | Main arena 无需维护多个堆,因此也无需 heap_info。当空间耗尽时,与 thread arena 不同,main arena 可以通过 sbrk 拓展堆段,直至堆段「碰」到内存映射段; |
结构的记录的信息包括:
- 堆对应的arena的地址
- 上一个heap_info的地址
- 当前堆的大小
- 用于对齐
malloc_state
用于管理堆,记录每个arena当前申请的所有内存的具体状态。
无论是main arena还是thread arena,都只有一个malloc state结构。对于main arena,这个结构是一个全局变量,放在libc.so的数据段中;对于thread arena,这个结构会放在最新申请的arena中
malloc的时候做了什么
(以ptmalloc为例)
- 获得锁或用mmap()开辟出非主分配区
- 将申请的内存大小转换为实际分配的内存大小
1 | malloc寻找堆块的顺序: |
- 大循环
- 按照 FIFO 的方式逐个将 unsorted bin 中的 chunk 取出来
如果是 small request,则考虑是不是恰好满足,是的话,直接返回。
如果不是的话,放到对应的 bin 中。
__int_malloc的大循环主要用来处理unsorted bin。如果整个循环没有找到合适的bin,说明所有的unsorted bin的大小都不满足要求
- malloc_consolidate:用于将fastbin中的chunk合并,清空fastbin。
先尝试向后合并,然后尝试向前合并:
如果向前相邻topchunk则直接合并,如果不相邻则尝试向前合并后插入unsortedbin, 然后获取下一个空闲的chunk,直到fastbin清空
堆分配函数
- malloc
- calloc
1
2
3
4calloc(0x20);
//等同于
ptr=malloc(0x20);
memset(ptr,0,0x20); - realloc
1 | 当 realloc(ptr,size) 的 size 不等于 ptr 的 size 时 |
free的时候发生了什么
源码
__libc_free
只有一个参数,为需要free的地址判断:
- 是否hook了(有则执行free_hook,结束free)(下)
- free的参数,为NULL直接返回
- (指针指向chunk头部)
- 如果内存是mmap得到的则进行munmap_chunk(),否则执行_int_free(参数为main_arena结构体的地址、header、0)
- free_hook:
判断是否有用户自定义的函数,如果有就执行,然后结束堆释放
__free_hook漏洞:如果将__free_hook变为一个system的地址,那么就可以执行这个system的地址
_int_free
检查
- 不能指向非法地址
- 指针对齐2*SIZE_SZ(32位下=4;64位下=8)
- free的空间大小小于限制最小的chunk
如果检查没有问题就在各个bin分支进行判断
fastbin
如果size小于等于fastbin的最大size且不与top chunk相邻,就进入fastbin分支进行判断,符合条件就插入fastbin头部,成为第一个chunk检查:
- 下一个chunk大小小于2*SIZE_SZ
- 下一个chunk大小小于system_mem(系统分配的空间总量)
在结构体malloc_state最后:
1 | /* Memory allocated from the system in this arena. */ |
- 设置chunk的mem部分为perturb_byte
1 |
|
perturb_byte:
1 | static int perturb_byte; |
- set_fastchunks,对arena的flags标志位的最低bit清零
- 用chunk的大小判断应该放进哪个fastbin中
- 对应fastbin的头指针初始化为NULL
- automically插入链表:
- chunk的fd赋值为fastbin的值
- fastbin赋值为当前chunk的地址
- 简单的double free检查,如果top of bin和当前free对象相同则报错,bypass方法为
1 | free(a) |
- fastbin entry 判断
1 | if (have_lock && old != NULL |
另外还有一些多线程的操作没有记上
free一个fastbin的过程只进行了一些判断和链接操作,对inuse位没有处理
代码
想把代码放上来,但是折叠之后不知道怎么高亮…
从:
https://code.woboq.org/userspace/glibc/malloc/malloc.c.html#4232
到4301行
非fastbin
包括smallbin、largebin、unsortbin
consolidate&&free
合并区块的顺序:先考虑物理低地址的空闲块,合并后的chunk指向合并的chunk的低地址
步骤:
- 获得下一个chunk的地址
- 3个double free check
1 | /* Lightweight tests: check whether the block is already the |
- 调用free_perturb函数
- 向后合并
1 | /* consolidate backward */ |
- 向前合并
- 如果下一个chunk不是top chunk,则合并高地址的chunk,并将合并后的chunk放入unsorted bin
1 | if (nextchunk != av->top) { |
- 如果下一个chunk是top chunk,则合并到top chunk中
1 | /* |
- 向系统返还内存
如果合并后的chunk大小大于fastbin_consolidation_threshold(默认64k),就向系统返还内存
1 | /* |
- 释放mmap出的内存
1 | else { |
tcache
glibc2.26后引入的技术,提升堆管理的性能,也舍弃了很多安全检查
引入了两个结构体"tcache_entry"和"tcache_perthread_struct"
- tcache_entry用单向链表的方式连接大小相同的空闲chunk结构体;
- 每个线程会维护一个tcache_perthread_struct,作为tcache的管理结构,维护tcache_max_bins个计数器和tcache_max_bins项tcache_entry,规定每条tcache_entry最多有七个chunk
工作方式
- 第一次 malloc 时,会先 malloc 一块内存用来存放 tcache_prethread_struct 。
- free 内存,且 size 小于 small bin size 时
- 先放到对应的 tcache 中,直到 tcache 被填满(默认是 7 个)
- tcache 被填满之后,再次 free 的内存和之前一样被放到 fastbin 或者 unsorted bin 中
- tcache 中的 chunk 不会合并(不取消 inuse bit)
- malloc 内存,且 size 在 tcache 范围内
- 先从 tcache 取 chunk,直到 tcache 为空,tcache 为空后,从 bin 中找
- tcache 为空时,如果 fastbin/smallbin/unsorted bin 中有 size 符合的 chunk,会先把 fastbin/smallbin/unsorted bin 中的 chunk 放到 tcache 中,直到填满。之后再从 tcache 中取;因此 chunk 在 bin 中和 tcache 中的顺序会反过来
参考:
https://blog.csdn.net/qq_17713935/article/details/86231502
Linux堆内存管理深入分析(上)
Linux堆内存管理深入分析(下)
ctf-wiki
https://zhuanlan.zhihu.com/p/77316206