python 爬虫学习
就此开一篇单独记录 py 爬虫的学习以及实操中遇到的问题(可能吧)
(分割线用(***或—))
爬虫入门
以下为 mooc 上 BIT 嵩天老师课程Python 网络爬虫与信息提取的学习
requests 库
安装
管理员打开 cmd,安装 requests 库
1 | pip install requests |
tip: pip 下载超时(timeout)
cmd 输入指令:
- pip --default-timeout=100 install -U pip
或
- pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
(升级 pip 后更换为的清华镜像)
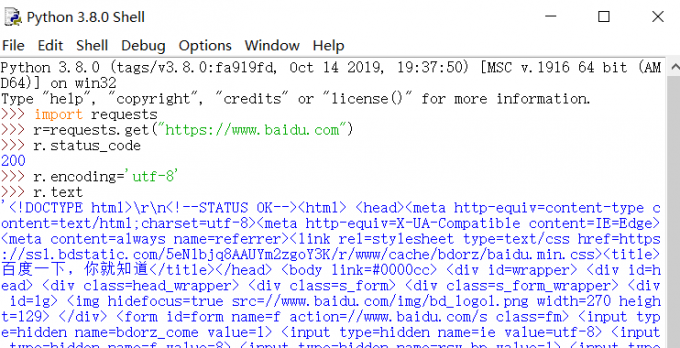
r=request.get(url)
构造一个向服务器请求资源的 request 对象,返回一个包含服务器资源的 response 对象
response 对象包含了服务器返回的所有信息

r.apparent_encoding: 根据网页内容分析出的编码方式
r.encoding: 如果 header 中不存在 charset,则默认编码为 ISO-8859-1
爬取网页的通用代码框架

1 | import requsets |
try:python 捕捉异常语句,详见:https://www.runoob.com/python/python-exceptions.html
requests 库主要方法

requests.request(method, url, **kwargs)
requests.get(url, params=None, **kwargs)
requests.head(url, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.delete(url, **kwargs)
**kwargs:
- params:字典或字节序列,作为参数添加到 url 中
- data:字典、字节序列或文件对象,作为 request 的内容
- json:json 格式的数据,作为 request 的内容
- headers:定制 header
- cookies
- auth
- files:传输文件
- timeout:设定超时时间,单位为秒
- proxies:设置代理服务器
- allow_redirects
- stream
- verify
- cert
爬虫尺寸
小规模:爬取网页。数据量小,速度不敏感。使用 requests 库
中规模:爬取网站。数据量大,速度敏感。使用 scrapy 库
大规模:爬取全网。(搜索引擎)
限制爬虫
- 来源审查:判断 user-agent
- robots 协议
robots 协议
Robots Exclusion Standard
网络爬虫先识别 robots.txt 再进行爬取
robots 协议时建议而非约束性,不遵守的话存在法律风险(类人行为可不参考 robots 协议)
拒绝被爬:尝试修改 user-agent
搜索引擎关键词提交
百度:https://www.baidu.com/s?wd=关键词
1 | keyword="xxxx" |
图片的爬取和存储
1 | url="....../...jpg" |
BeautifulSoup 库
BeautifulSoup 库是一个解析、遍历、维护标签树的功能库
安装
cmd 下
1 | pip install beautifulsoup4 |
使用:
1 | from bs4 import BeautifulSoup |
作用:html 文档 ↔ 标签树 ↔beautifulsoup 类
BeautifulSoup 基本元素

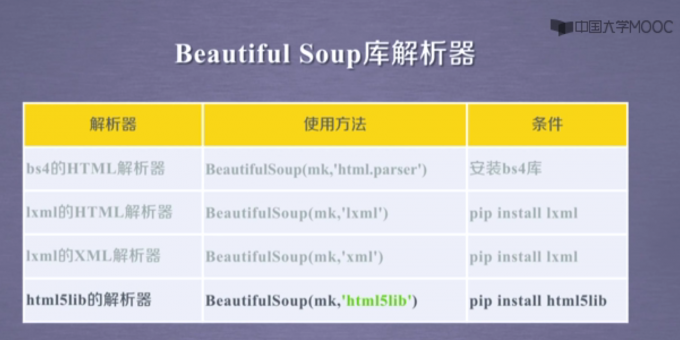
例:
打印标签
1 | import requests |
html 内容遍历
html–树形结构
遍历:下行遍历、上行遍历、平行遍历
下行遍历:

1 | for(child) in soup.body.children: |
1 | 获得子节点的数量: |
ps:'儿子节点’这种叫法听起来真是贼奇怪
上行遍历:

1 | 查看父标签: |
平行遍历:
发生在同一个父节点下的各个节点间
平行遍历获得的下一个结点不一定是标签类型

1 | 查看下一个平行标签: |
Prettify
作用:在每个标签后添加换行符,print 的时候易于阅读
使用方法:
1 | print(soup.prettify()) |
以上为 2020.3.16-2020.3.21
正则表达式
regular expression (RE)
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 任何单个字符 | |
| [ ] | 字符集 | [abc]:a、b、c; [a-z]:a~z 单个字符 |
| [^ ] | 非字符集 | [^abc]: 非 a、b、c 的单个字符 |
| * | 前一个字符 0 次或无限次扩展 | abc *:ab、abc、abcc… … |
| + | 前一个字符 1 次或无限次扩展 | abc *:abc、abcc… … |
| ? | 前一个字符 0 次或 1 次扩展 | abc *:abc、abcc… … |
| \ | 左右表达式任意一个: abc\ def :abc 或 def | |
| {num} | 扩展前一个字符 m 次 | ab{2}c:abbc |
| ^ | 匹配字符串开头 | ^abc:abc 在字符串的开头 |
| $ | 匹配字符串结尾 | $abc:abc 在字符串的结尾 |
| ( ) | 分组标记,内部使用\ | 操作符 (abc):abc; (abc |
| \d | 等价于 0~9 | |
| \w | 等价于 A ~ Z, a ~ z, 0 ~ 9, _ |
https://www.runoob.com/regexp/regexp-tutorial.html
Re 库
调用方法
1 | import re |
表达式的表达类型
raw string:不包含转义符(\)的字符串
string 类型(将’‘理解为转义符)
raw string 如:r’[1-9]\d{5}‘、r’\d{3}-\d{8}\d{4}-\d{7}’
string 如:[1-9]\\d{5}‘\\d{3}-\\d{8}\\d{4}-\\d{7}’
主要功能函数

- re.search(pattern,string,flags=0)
- re.match(pattern,string,flags=0)
- re.findall(pattern,string,flags=0)
- re.finditer(pattern,stirng,flags=0)
pattern: 正则表达式的字符串或原生字符串表示
string:待匹配字符串
flags:正则表达式使用时的一些控制标记,包括:
re. I:ignorecase, 忽略大小写
re. M:multiline, 使用’^‘时将每行都当作匹配开始
re. S:dotall, 让’.'匹配所有字符,包括换行符
- re.search(pattern,string,maxsplit=0,flags=0)
maxsplit: 最大分割数,限制分割的数量为 n,将剩下的所有部分输出为第 n+1 个
- re.sub(pattern,repl,string,count=0,flags=0)
repl: 替换的字符串
count:替换的最大次数
以上为2020.03.22-2020.03.28
RE库的match对象
用 type(match)检查 match 的类型


贪婪匹配和最小匹配
re库默认采用贪婪匹配,即输出匹配最长的子串
Scrapy库
scrapy爬虫框架安装
1 | pip install scrapy |
scrapy 爬虫框架结构
5个主体+2个中间件
3个主体(engine+downloader+scheduler)为已有实现
2个主体(item pipelines+spiders)为用户配置:
item pipelines对获得信息进行处理
spiders提供url和解析网页的内容
**以下3个不需要用户配置
engine控制所有模块之间的数据流,根据条件触发事件
downloader根据请求下载
scheduler对所有爬取进行调度
在以上三个中有一个中间件:downloader middleware
scrapy库爬虫常用命令
格式:scrapy
一个工程是最大的单元(大的scrapy框架),其中有多个spider

实例
…
实例
中国大学排名爬取
数据来源:软科中国最好大学排名2019
- 获取网页内容:gethtmltext()
- 提取信息到合适的数据结构:fillunivlist()
- 输出结果:printunivlist()
1 | import requests |