非定期のDiary
…
检测复用c/c++组件带来的1day。目前有基于版本和基于代码的方法,基于代码的方法在代码修改后复用的场景下,检测结果可能会带来大量误报和漏报。
本文结合了这两类方法
好早之前记录的东西了,放出来罢
在平板上用termux跑ubuntu+vim写/看代码时的记录
不日应该会改成用带gui的aidlux或者ubuntu+code-server
不知道会不会再往这上边添加东西
正常发挥的话明年年初能发一篇论文,故稍微了解了一下这些名词到底是啥orz不然也太离谱了
工具名称:BinXray
实验
比较的工具:
工具名称:Sigmadiff
比较的工具:diaphora(目前已知仅存的伪代码diffing工具)、deepbindiff(仅存的二进制基本块级别diffing)
思想:用IR表示的过程间程序依赖图(IPDG)、DGMC匹配IPDG的结点
IR表示的优点:简洁、更丰富的语义信息、token level的细粒度、跨架构
挑战:在strip的文件里需要推断高级的特征,并可能引入噪声。
流敏感、call-site敏感的lightweight symbolic analysis提取IR语义信息:
motivating:在伪代码里找到语义等价的token级变化,忽略句法的改变。伪码层面的改变带来的挑战(感觉2、3主要还是编译的问题)1.变量重命名(但是在cots文件里应该没有这个问题?);2.表达式合并或拆分;3.控制流变化。作者在此处进行了实验,表明伪码的diffing不适合直接使用源码diffing技术
Step1:预处理。构造IPDG,结点为IR语句,边(两种)表示控制流和数据流;语义提取,过程内符号执行算法,得到结点的特征,具体算法建议看论文
Step2: 伪代码diffing
与人类基因计划(human genome project)相似的结构来构造“软件基因计划(SGP)”。
事实证明想过只要背原题
创建一个non-shared项目,打开BSim功能(v11.0 默认关闭)
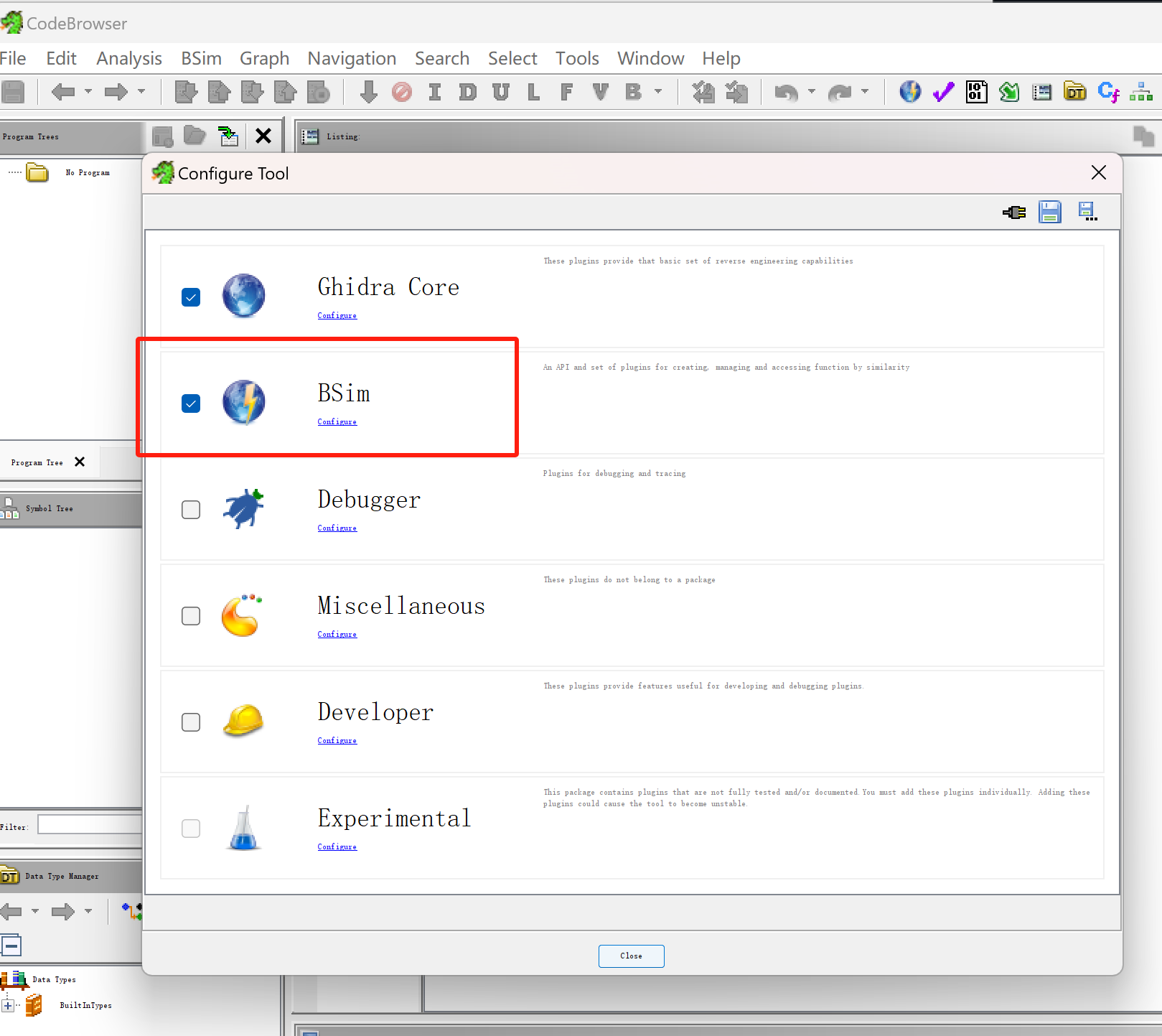
执行CreateH2BSimDatabaseScript.java脚本,修改name和dir字段,其他不修改。
分析一个二进制文件
执行AddProgramToH2BSimDatabaseScript.java脚本,使用name.mv.db数据库。脚本执行后会把这个二进制文件的函数签名加入数据库中
在BSim的菜单栏里选择Manage Servers指定database
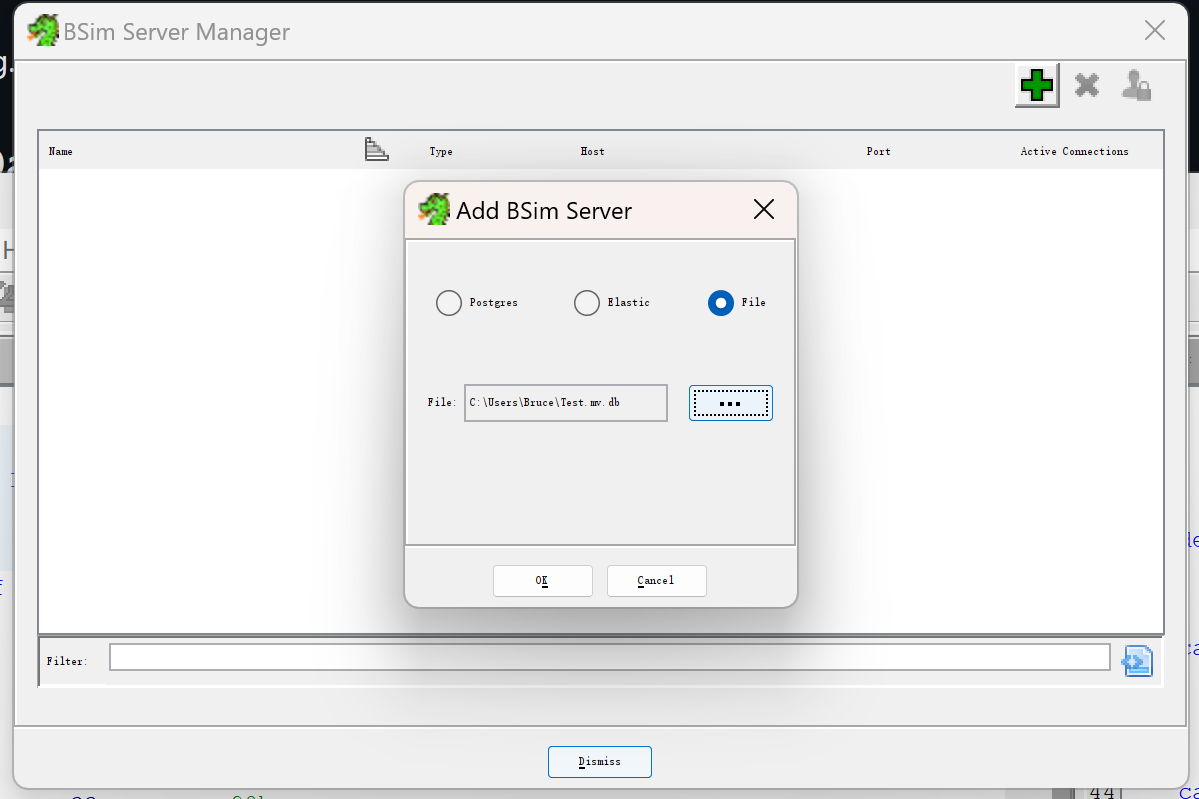
把当前code view窗口选定的函数和database里的进行匹配,可以设置相似阈值和置信度阈值,也可以指定条件(二进制文件名、架构、调用了xx外部函数)
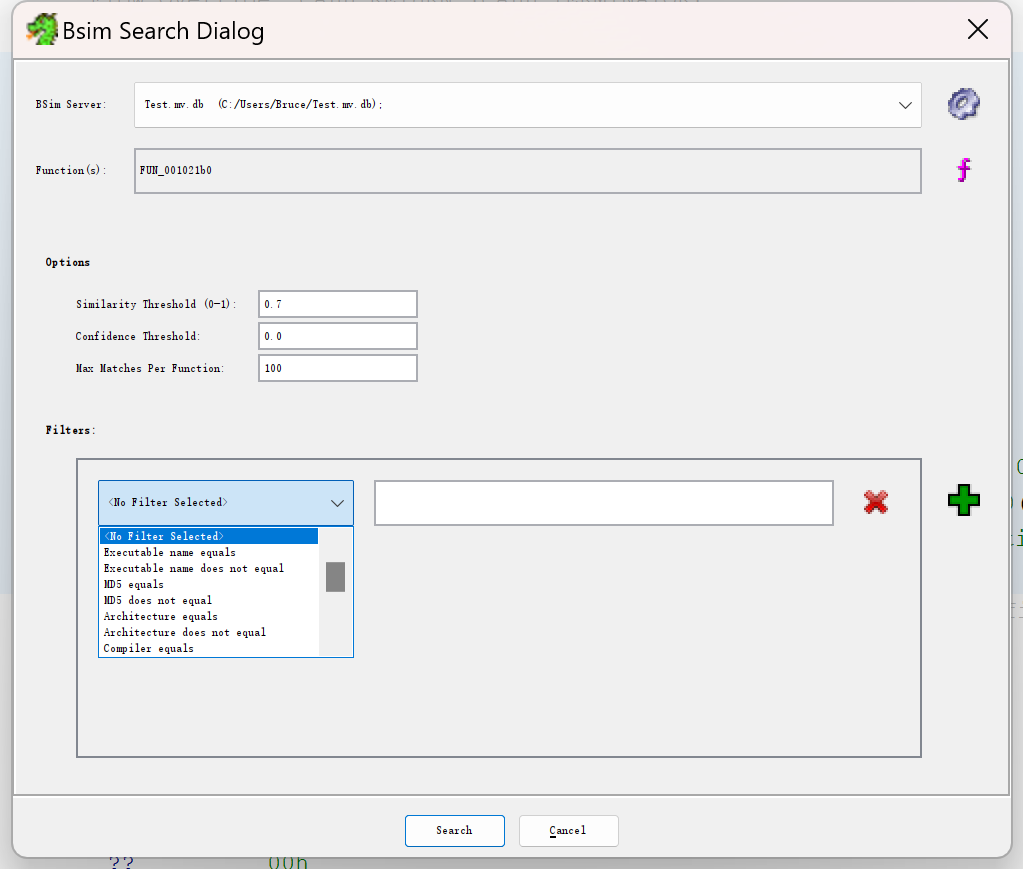
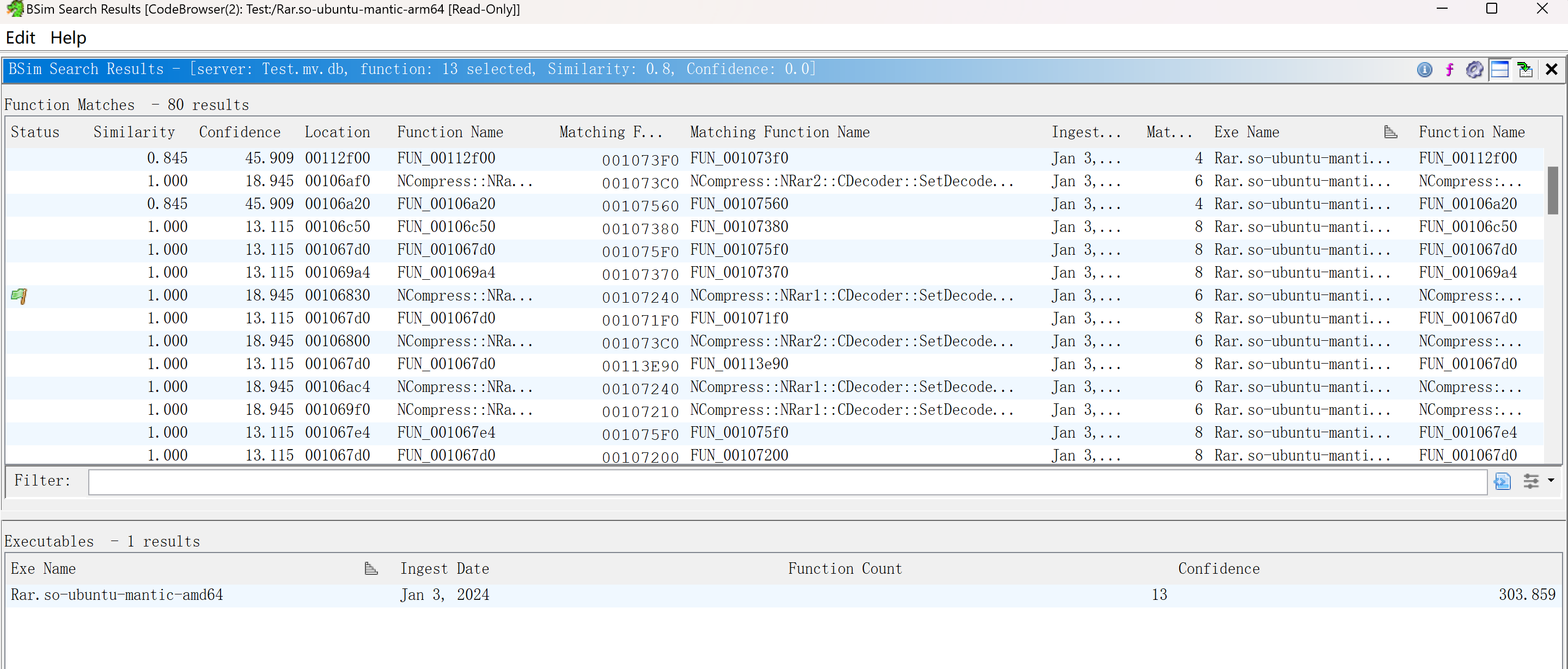
得到结果
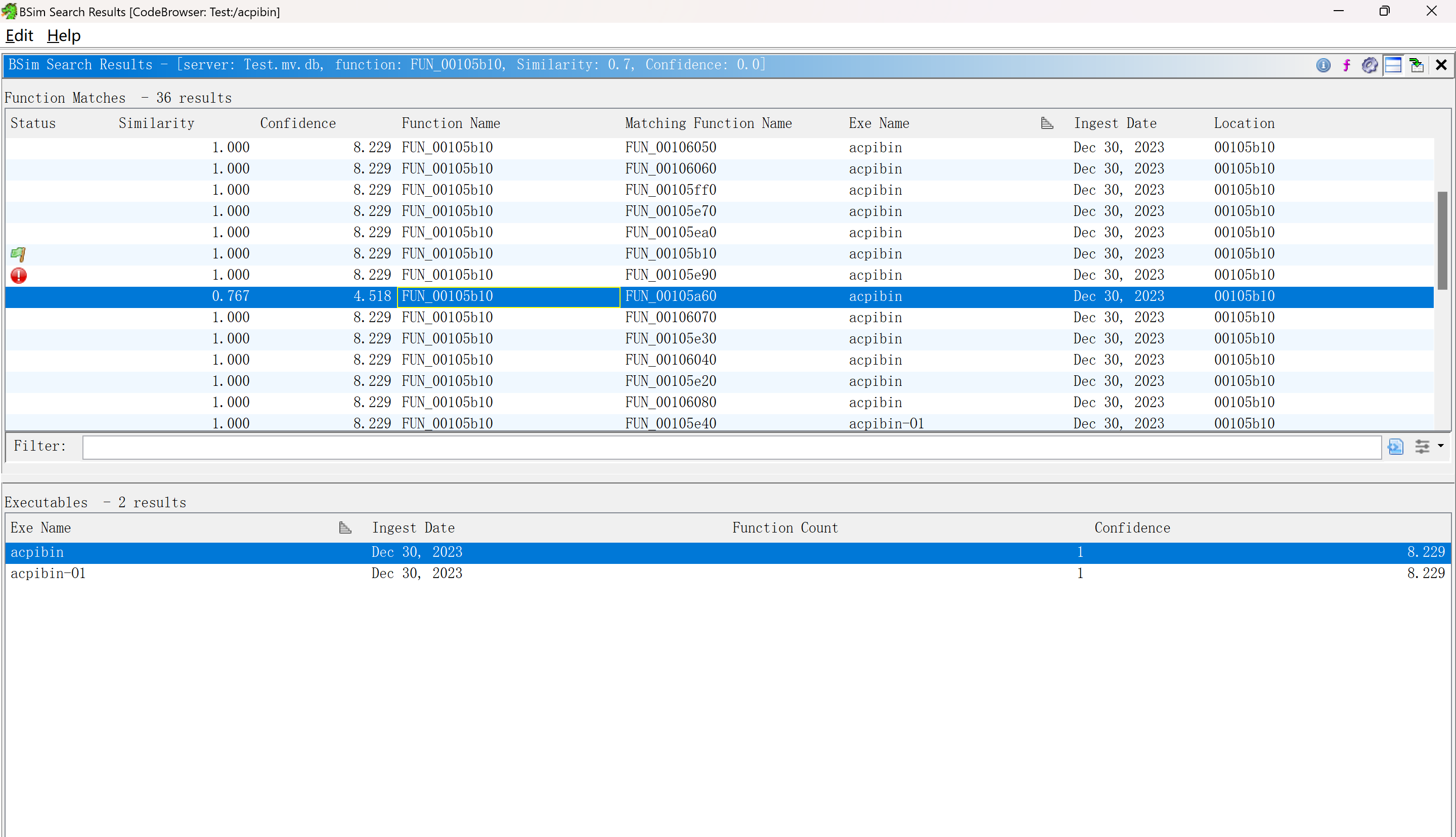
比对的结果默认包含整个database里的函数,因此也包含了该二进制文件里的函数
可以对匹配到的函数名字进行替换、比对伪代码和汇编代码
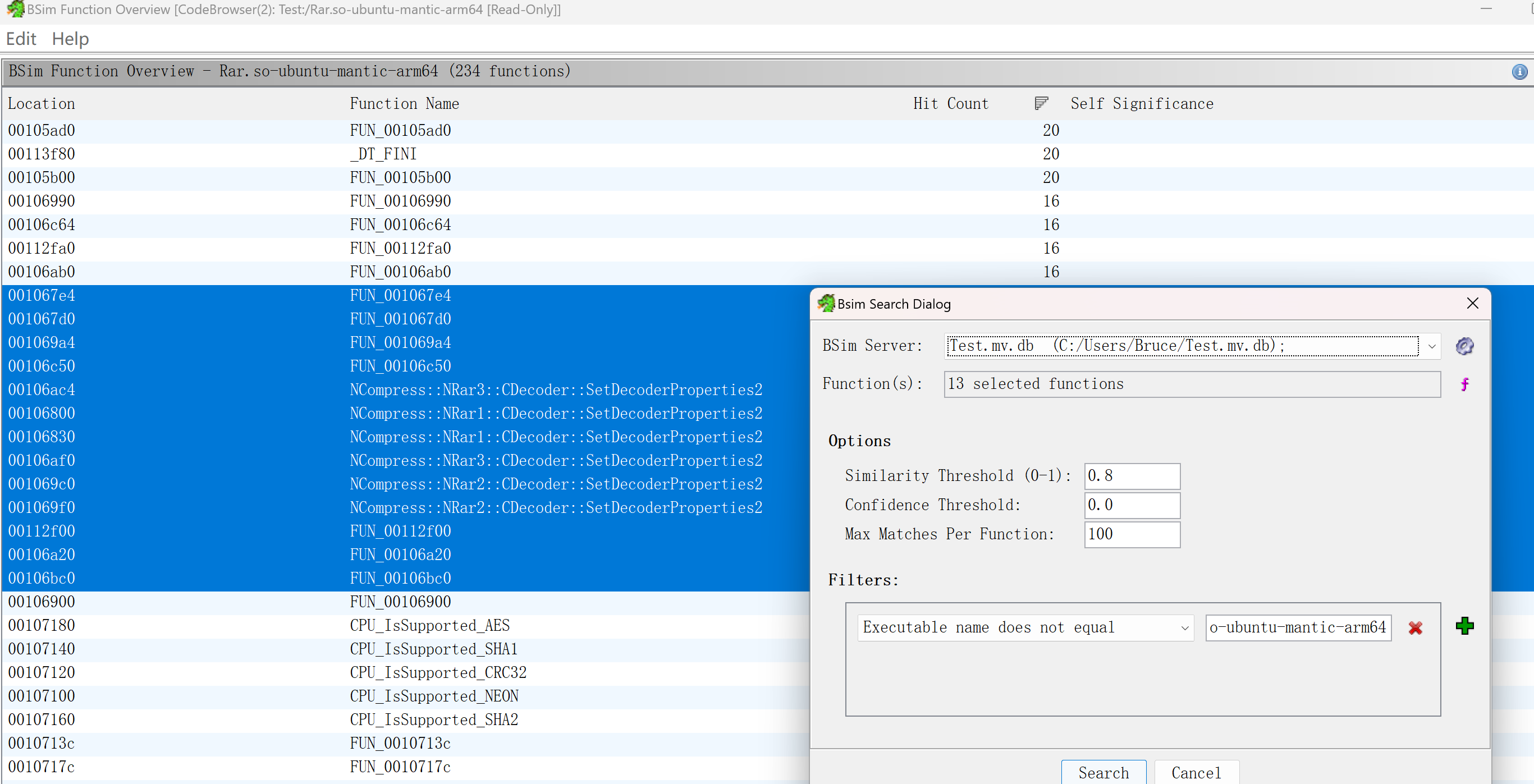
在code browser里选择bsim->code overview,选择多行进行search可以在一个result窗口查看多个函数的匹配结果
TO BE CONTINUED …
可以从这些脚本(部分)去看BSim的相似度、置信度的计算规则
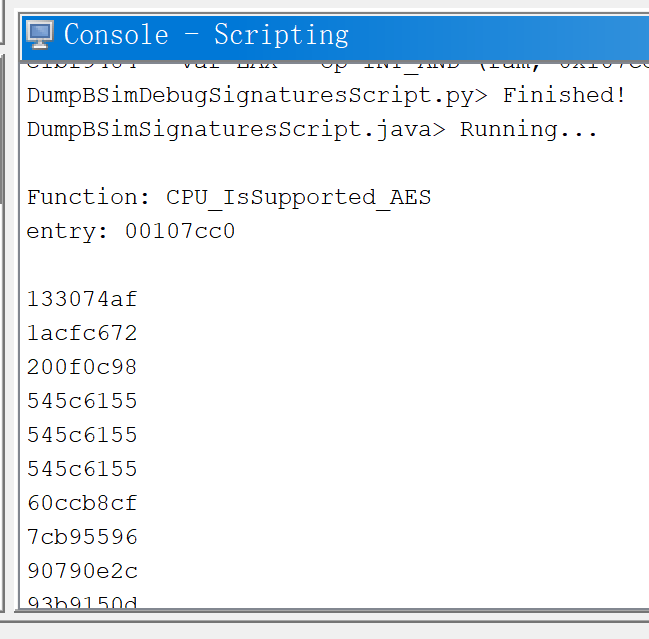
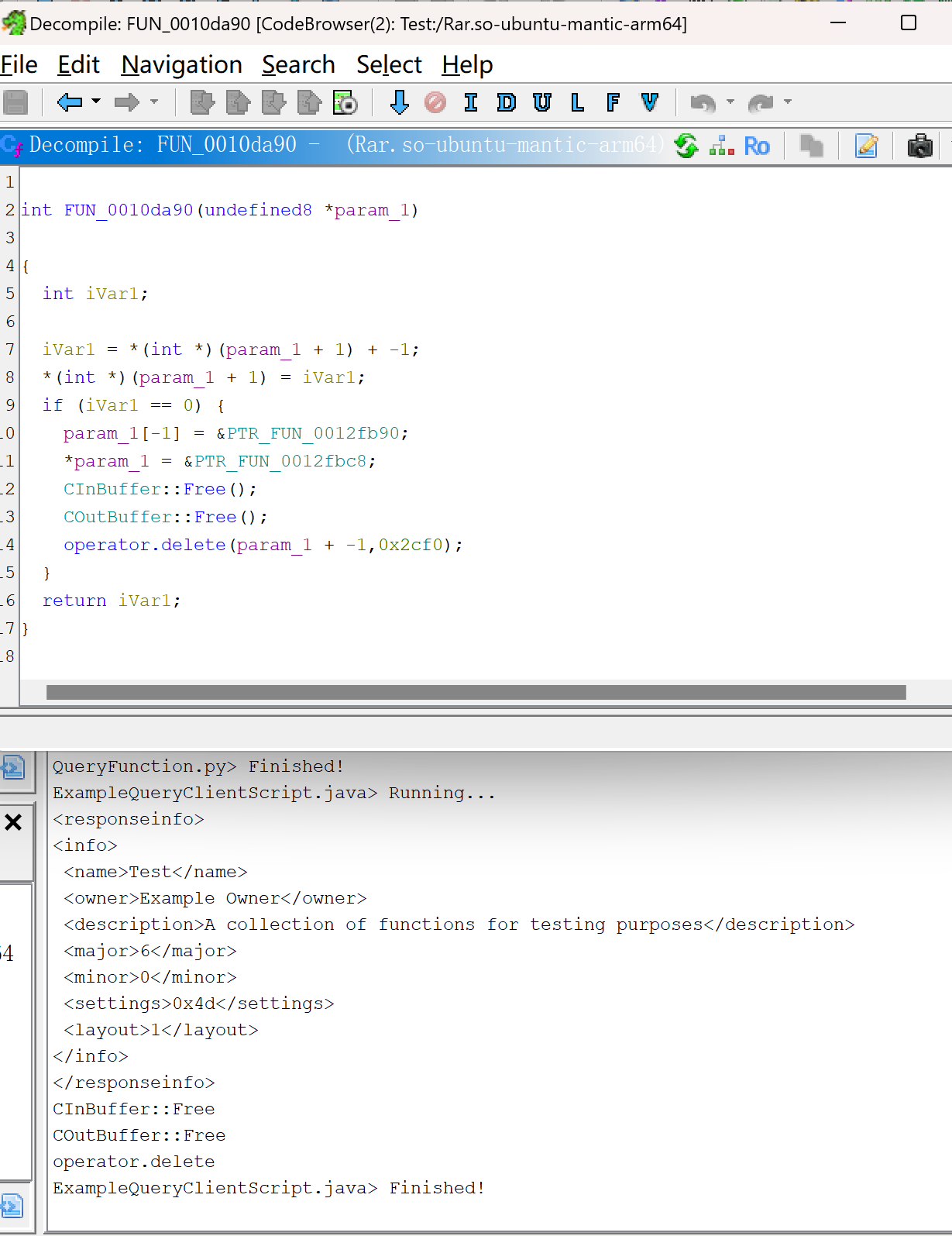
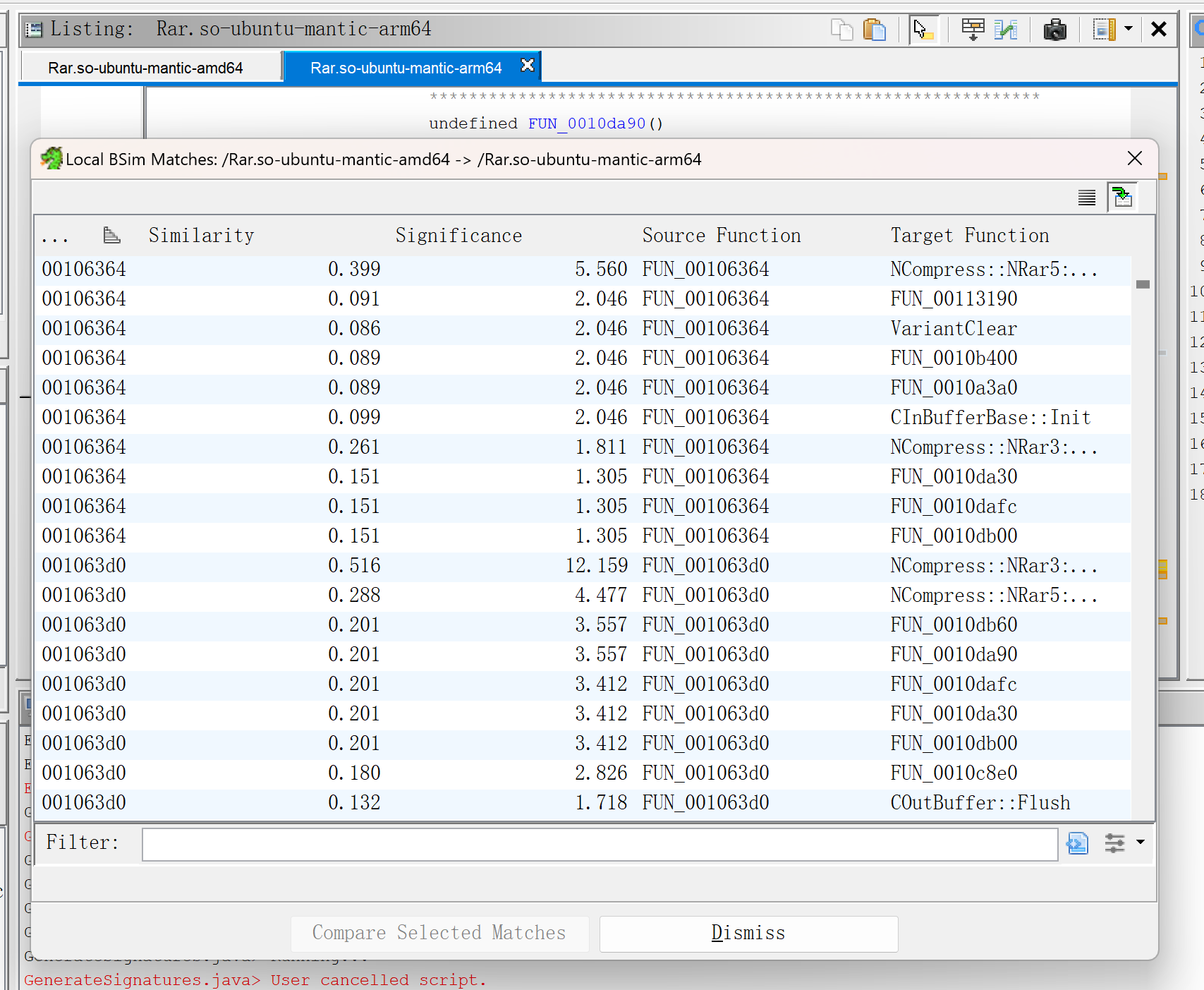
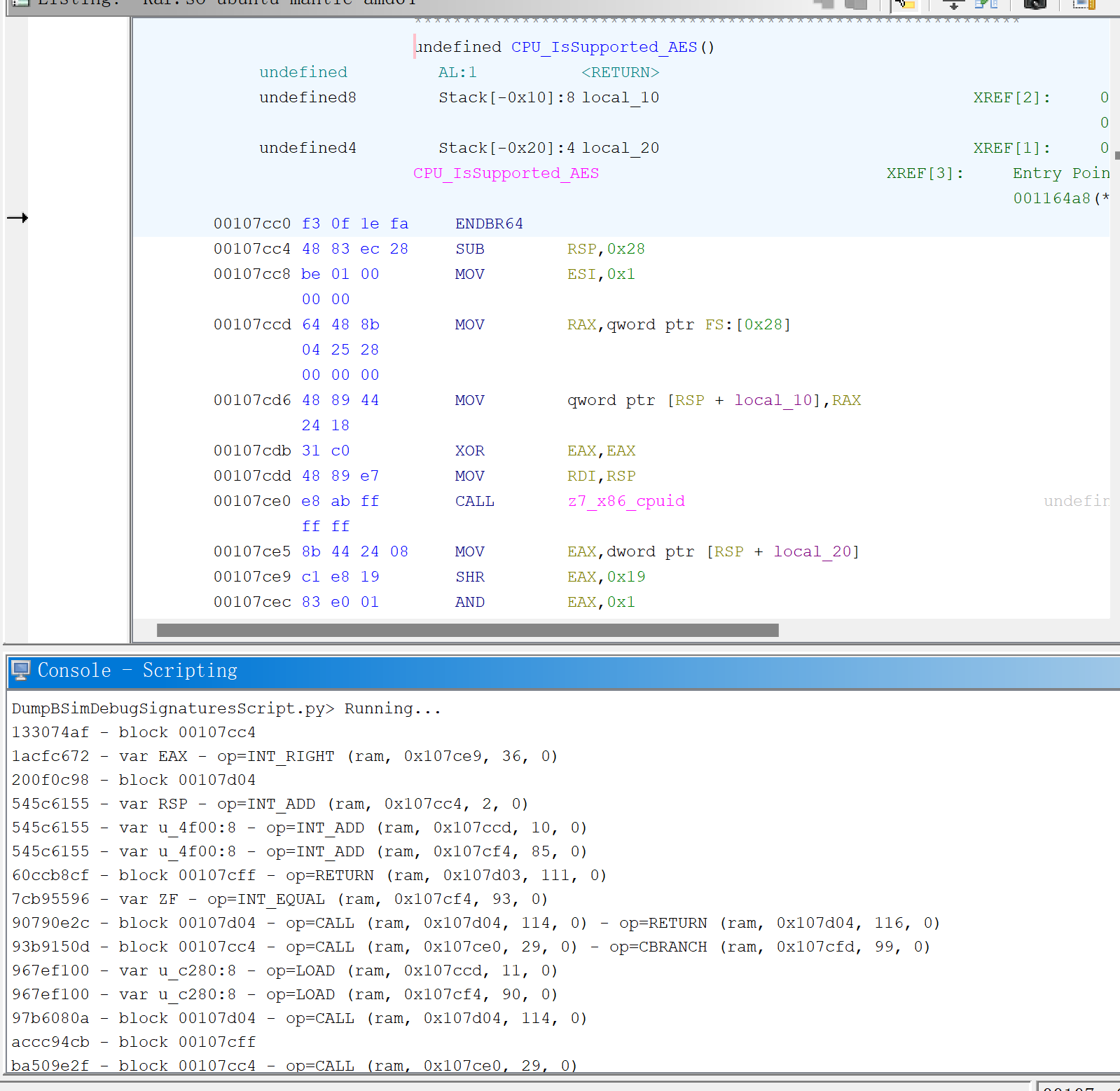
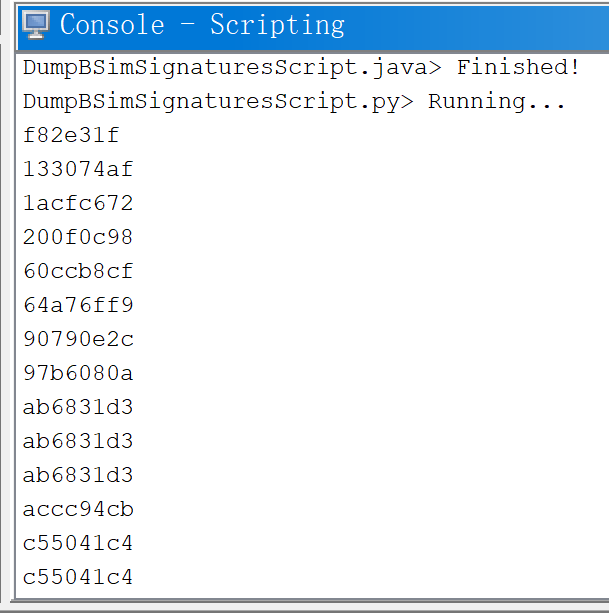
由于BSim会得到多个匹配结果,并且相似度值可能都相同,函数A的结果也可能和函数B匹配到的存在重复,因此比较fn,fp等对其他工具较为不公平。
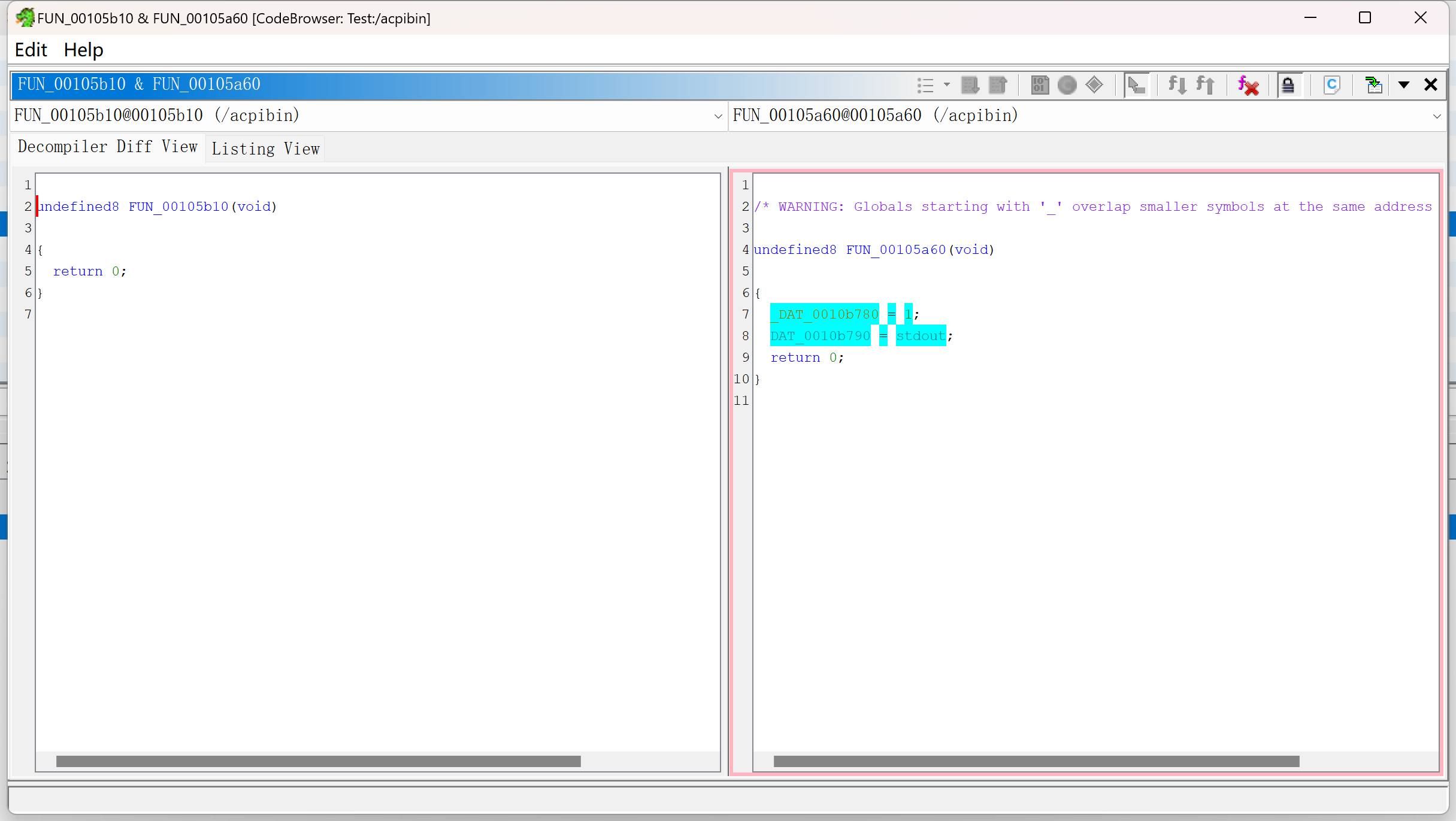
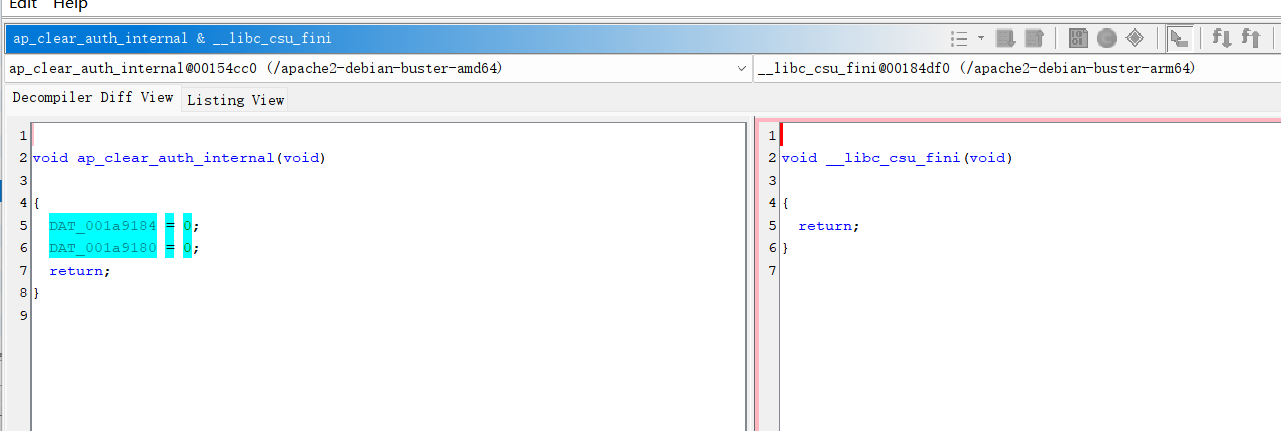
青绿色的是函数的差异
当用光标进行选择时,粉色是bsim关注的并且产生匹配的token;淡紫色是bsim关注但是没有匹配到的token;橘色表示token不会用作匹配
以下两对的相似值分别为1和0.777
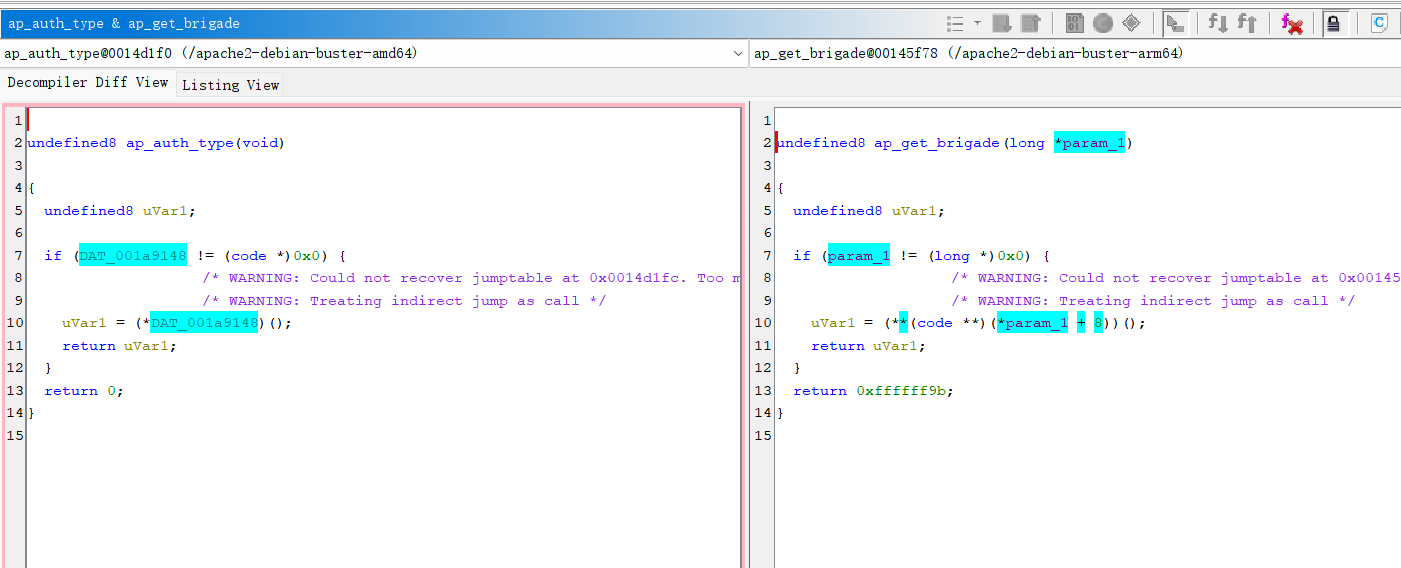
排除了较低hitcont和较小的函数
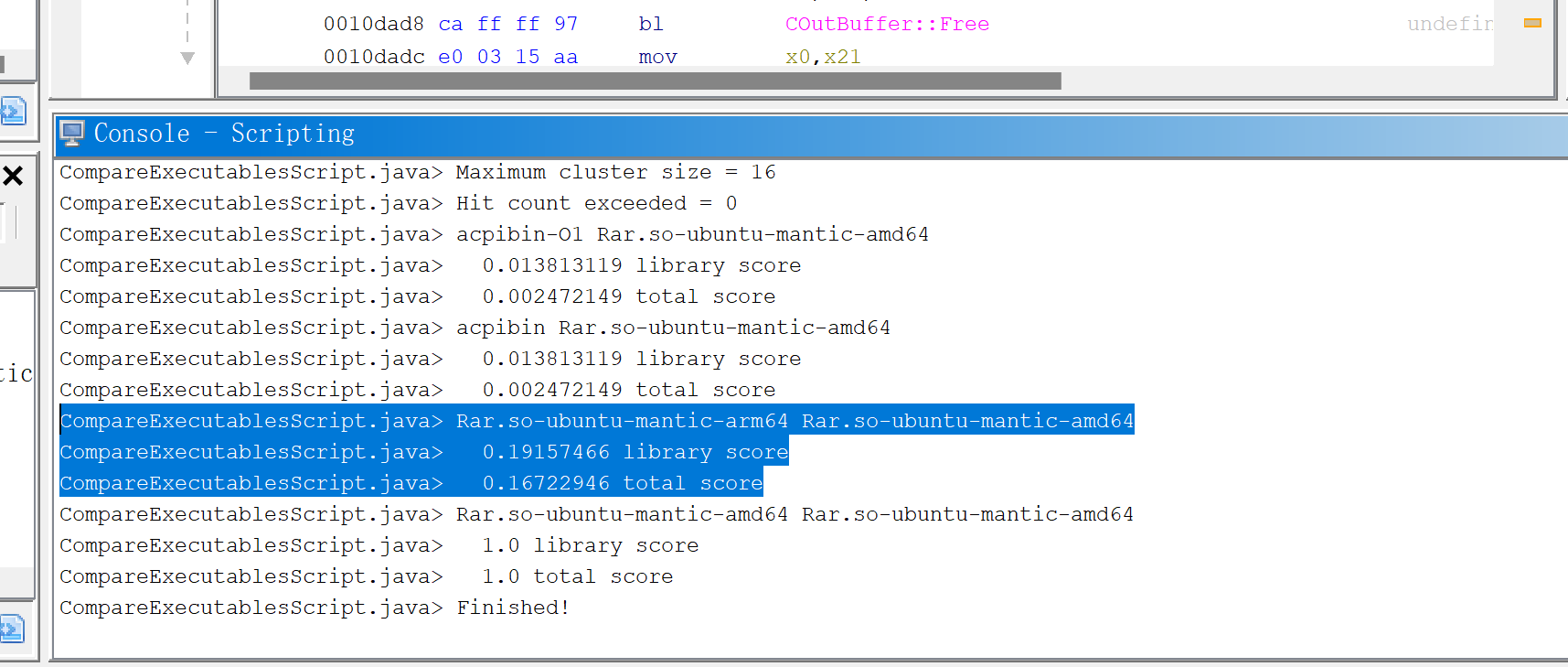
library score:当较小的二进制在另一个二进制里全都能找到匹配则为1
用提供的脚本跑的跨架构的例子,得到的文件相似度很低
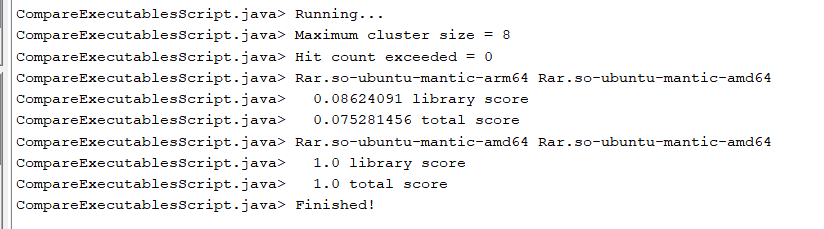
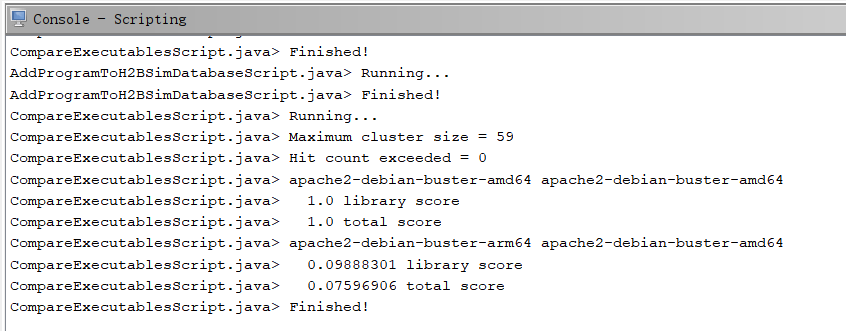
由于一个待匹配函数会得到多个匹配的结果,因此把这些结果都视为匹配


看 https://github.com/fkie-cad/cwe_checker 的一些记录,目标是fix一个bug